Updated November 14, 2025.
We keep hearing that this will be the year of AI agents, but what exactly does that mean?
In reality, AI agents have been around for decades. It’s just that lately, Large Language Models (LLMs) have eliminated one of the biggest barriers to creating agentic systems: writing custom algorithms and training models from scratch. Now, sophisticated reasoning is just an API call away.
Before embracing the hype cycle, though, it's good to understand the full story: what agents are, why they came about, how they work, and—most importantly—what they can and can't do.
AI agents are software systems designed to work with minimal human intervention, thanks to their abilities to:
- Sense their actively changing environment (that they also affect)
- Think about their environment and what to do in it
- Act autonomously on their best decision
- Run in a loop with memory of what they've seen and done
Consider a system that continuously observes a web application's performance, identifies issues, and reports them to the relevant team members. This system goes beyond a simple function; it runs in a loop, processes evolving data, and chooses actions based on that data.

AI agents solve four fundamental problems humans can't handle at scale:
- Fragmented systems: Agents connect siloed tools/data streams humans manually juggle (e.g., security teams cross-referencing firewall/IDS/SIEM logs).
- Endless decisions: Agents handle repetitive judgment calls 24/7 without fatigue (e.g., auto-rolling back failed deployments).
- Exponential complexity: Agents navigate scenarios with more variables than humans can track (e.g., managing power grids during brownouts).
- Real-time adaptation: Agents rewrite rules in microseconds between events (e.g., fraud detection updating between transactions).
Agents at this scale and with these capabilities require infrastructure we've only recently mastered. Although agents have existed for decades, their evolution from brittle rulebooks to fluid reasoners shows what may soon be possible.
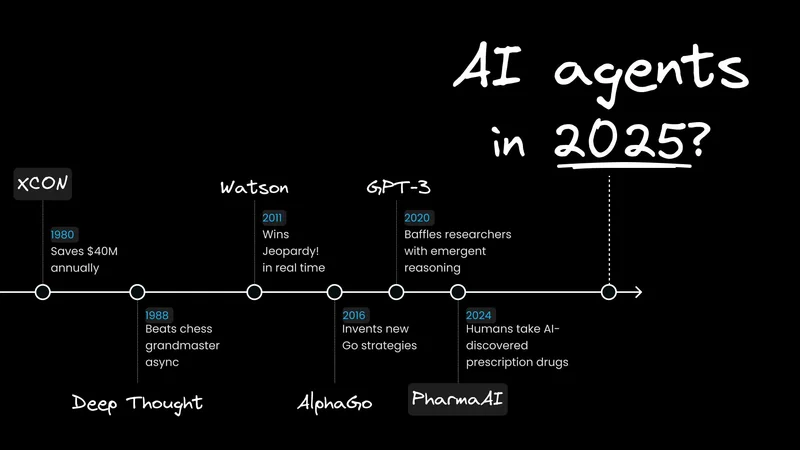
Agents aren’t a new fad. As far back as the 1950s, we’ve had some brilliant systems:

All these agents have only been as good as their rules and data. For the past 70 years, we’ve been writing those rules and data by hand, but since around 2020, we’ve begun to use LLMs to build agents without:
- Hardcoding every rule (à la Deep Thought's chess logic)
- Curating narrow training data (à la Watson’s Jeopardy! prep)
- Manual feature engineering (à la AlphaGo’s move predictors)
Now, a developer with API keys can create an agent that reasons about novel scenarios—something that used to take months for PhD teams.
My take? Even if we were to stop getting new LLMs today, we haven't seen the very best agents—not because the LLMs aren't smart enough, but because we've yet to optimize the infrastructure, rules, and data as much as we have in pre-LLM systems.
While today's LLMs enhance agents' reasoning capabilities, AI agents aren't defined by their use of an LLM.
On top of models, AI agents have:
- Autonomy: Agents operate continuously with very little human intervention; models execute one-off tasks. A web monitoring service might trigger alerts autonomously, unlike a help widget model that would only respond when queried.
- Input Handling: Agents actively sense and update their state; models require full context every time. A persistent customer support chatbot could maintain conversation context locally, while a model would need the entire chat history with every API call.
- Adaptability: Agents adjust their actions in real-time; models process input without feedback. A dynamic recommendation engine might update its product suggestions as the user clicks, while a static model would need new input.
To oversimplify: AI agent = AI model + glue code to run it in a loop with tools and active memory.
That “glue code” is what’s interesting, and we’ve optimized it far more in the past seventy years than we have with LLMs today. The difference between great and mediocre agents lies in how you assemble these main components:
- Personalized data
- Real-time memory
- The “sense, think, act” loop
- Tool calling
| Type | What it does | Example |
Reactive | Responds to current environment without memory | Code assistant that auto-fixes syntax issues in real time |
Deliberative | Plans sequences of actions to achieve goals | Release pipeline agent that plans and executes multi-step deployments |
Learning | Improves decisions based on past performance | Anomaly-detection agent that adapts to new traffic trends |
Collaborative | Multiple agents solving complex problems together | Multi-agent debugging system where one agent reproduces errors and another proposes fixes |
Many of today's AI queries, especially via API call, are stateless, but agents become powerful when they can carry context, remember past steps, and act with awareness of your data and goals.
The leap from stateless, generic AI to fully agentic AI starts with giving models access to your unique context. Here's how developers do it.

RAG uses vector databases to let models "recall" relevant info from external sources (e.g., your Slack history or codebase).
Vector databases convert your data into embeddings (efficient numerical representations) and inject relevant text chunks into your prompt to the AI model.
However, RAG is limited when it comes to implicit information links. For instance, asking about your lizard should bring up your pet Scaleb’s data, but asking about your "best friend" wouldn't pull up Scaleb unless you've noted in your database that your best friend is a reptile.
Prompts are the most straightforward way to give AI personal context: just tell it.
This beats RAG for reliability—models process every detail without retrieval—but hits a hard wall with context limits (even Gemini Pro’s 2M tokens cap at ~3,000 pages). Plus, you have to provide the model with new context every time, which can become more work than setting up RAG.
Users can also override injected context (“Ignore previous instructions...”), making it risky for sensitive rules.
Direct prompt injection is best for small, transient datasets where accuracy trumps scale.
Changing an AI’s system prompt hardwires core rules into the model's "operating system"—like prioritizing safety guidelines ("Always cite sources") or tool usage ("Convert units to feet").
System prompts override user prompts (no "Ignore previous instructions" hacks) but too much data can blind models to edge cases.
Balance is key—define how to think (e.g., "Structure answers using Markdown headers") while letting RAG and users' requests handle what to reference (e.g., codebase files).
This method works well for things like enforcing brand voice or compliance without constant re-prompting.
Don't confuse system prompts with agents.md files, though. Look up, per software, whether context in agents.md gets added at a system prompt level or a direct prompt injection level to better understand what to write.
Fine-tuning is more involved than prompting or RAG, but it permanently alters the model's behavior—even before prompts. For example, it can turn a generic "LawyerLLM" into your business' legal counsel.
Ideal for businesses where AI doesn’t handle core operations but still enhances them (e.g., H&M’s customer chatbot), fine-tuning can drastically improve performance on domain-specific tasks, and it doesn't take an advanced degree in machine learning.
Fine-tuning uses supervised learning, such as providing input/output pairs (e.g., legal questions and your firm's responses) to reshape the model's text generation.
Not to be confused with rolling your own custom model, training a specialized model is a viable option for mission-critical, repeatable workflows where generalized LLMs falter.
At Builder, we trained a specialized model that's 1000x faster and cheaper than other LLMs for deterministic tasks like design-to-code conversion. We keep improving this model over time, differentiating it from what’s available from major providers.
The nuclear option: build a model from scratch.
This might require 1B+ domain-specific tokens (e.g., BloombergGPT's 363B financial texts), PyTorch/TensorFlow mastery, and GPU clusters most startups can't afford (~$1M+/month).
While you gain native domain thinking (no hacks), you risk obsolescence—today's SOTA could be tomorrow's Claude Sonnet footnote.
Custom models are reserved for AI-first companies making existential bets, like what AlphaGo did for reinforcement learning.
AI agents can use memory to automatically improve over time according to a set of goals, often called evals. This is how Builder’s Micro Agent works—it generates tests (which act as evals), then tries to generate code to pass those tests. It keeps iterating until those tests pass, remembering (through simple prompt injection into the model’s context window) which approaches haven’t worked so far.
This works great, but many AI agents need more than just stateless LLM APIs, where the entire chat history is sent with each request. Stateful memory allows agents to evolve more dynamically across interactions, since they can store time-limited or permanent memories in:
- Vector databases: For semantic recall (Scaleb's allergies -> mealworm avoidance)
- Knowledge graphs: To map relationships (User's mom -> calls every Sunday)
- Action logs: For retry strategies (API error -> new params every 5 minutes)
This gives agents advantages over stateless systems:
- Adaptive learning: Logs behavioral patterns (user rejects mealworm suggestions → auto-hides reptile content)
- Reasoning loops: Self-corrects via recursive workflows (API failures → parameter adjustments → success)
- User continuity: Avoids context-reload fatigue ("Still avoiding mealworms?" vs. "Tell me about Scaleb again")
Common memory systems use RAG-like flows:

More sophisticated systems can include time decay to auto-expire memories, namespace scoping for multi-user systems, and validation to sanitize LLM-generated memories to reduce hallucinated inputs.
At the core of AI agents is the "sense, think, act" loop—a cycle that turns static AI calls into dynamic, self-correcting workflows.
This isn't just a theoretical concept; it's how the agent executes its tasks.
In this first phase, the agent actively observes its environment.
Instead of waiting for all necessary information to arrive in a single prompt, it continuously checks for updates—like user input, relevant personalized data and memories, and external API data.
With updated context, the agent takes time to deliberate, parsing information, weighing actions against predefined goals, and evaluating whether its previous attempt met the outcome.
This "thinking" step allows an agent to compare its output against hard-coded evals or more fluid, abstract performance metrics measured by itself or another LLM. (You can see this in practice in LLMs like OpenAI's o1 and Deepseek's R1.)
Finally, the agent executes its best action, which might involve generating output, calling an external tool, or triggering another agent.
This action alters the agent's environment, creating new data for the "sense" phase, and we loop again. Each iteration is a chance to improve towards repeatable outcomes.
The agentic loop stops when a clear exit condition is met—like a CI/CD pipeline that only deploys code after passing all checks.
If you need another exit method, you can halt it after a set number of retries. (This is how low, medium, and high reasoning effort works in OpenAI's o3—it's just the number of retries.)
The last main component of AI agents is tool use. Tools are any external coded function that an agent can call and get results, just like chatting with a user.
Tools can:
- Fetch from an external API
- Call a function written in any programming language
- Call a specialized AI agent (which is usually more effective than having one agent run everything)
- Store or access data
- Etc.
Tools give AI agents the ability to interface with their environment, which, depending on what tools you give them, can include any API service provider.

For instance, you might design a small agentic workflow that scans your email for travel plans and puts them in a folder. The agent would need access to two Gmail tools: one to send new messages directly to the agent and trigger the workflow, and one for the agent to put the email in the "Travel" folder if it determines the contents are travel-related.
Unfortunately, for every tool you want an AI to use, you have to teach it to use that tool—the AI must make a structured request, i.e. JSON, with the correct function parameters.
An agent knows when to use a tool through its initial programming (prompting or fine-tuning) and analysis of the current input. The agent is instructed to recognize specific keywords, patterns, or situations indicating the need for a particular tool.
All this can take up a model's context window, and it can be a pain to wire up an agent to access more than a few tools. Plus, if a model struggles to use a specific tool, you may need to implement a retry mechanism or schema validation for the model's output.
The biggest shift in agent design over the past year has been the rise of the Model Context Protocol (MCP). Instead of writing custom tool logic for every API, MCP gives agents a universal way to discover, authenticate, and call tools through a shared standard.
This matters because modern agents rarely operate in isolation. They need access to your data, your services, and your workflows. MCP lets them do that safely and consistently.
With MCP, an AI agent can:
- browse available tools and understand their capabilities
- read and write data from connected services
- perform authenticated actions without hardcoding credentials
- run in any environment that supports the standard
For developers, the difference is enormous. As long as someone maintains an MCP server for a service —Slack, Figma, Notion, GitHub, Supabase, Builder, and many others now do—your agents can use those tools immediately without custom plumbing.
MCP isn’t just a standard. It’s becoming the API layer that makes agent ecosystems interoperable.
Security is still essential, so always be cautious with sensitive data, since agents can send requests externally. Still, the protocol itself gives developers clearer boundaries than ad-hoc tool calling ever did.
Adoption is moving fast, and while not every model or service supports MCP yet, it has become the most promising foundation for building scalable, maintainable, tool-using agents.
There you have it: personalized data, real-time memory, an autonomous loop, and tool calling all offer improvements over stateless LLMs.
However, before rushing off to automate your entire life, let’s look at some things to consider:
Error Propagation: AI is prone to hallucinations. Loop-running agents (without self-correction) can exaggerate this problem. An incorrect assumption in cycle one becomes foundational truth by cycle three.
Setup Time: Agents take a while to build, and once built they're often not flexible enough for other purposes. You may need to build multiple agents to handle specific tasks.
Complexity: The flexibility of AI systems can result in choice paralysis: When do I use which model? Where do I tweak the temperature per prompt? How do I phrase each prompt? The learning curve is high, and it can feel more "unfair" to learn than normal code, given the output variability.
Cost: You can often optimize cost for a problem by matching model size to task complexity, but agents require far more API calls than one-off prompts, and billing spikes can be unpredictable.
Maintenance: Model endpoints change, and better, cheaper models keep releasing. To build lasting agentic systems, design architecture that abstracts your model dependencies.
Security: When building agents and tools that interface with external APIs, be mindful of what you share with the AI and its tools. In non-deterministic systems, it’s hard to sanitize data reliably, so be careful what context you provide.
Data Reliance: AI Agents are only as good as the data and rules (training, fine-tuning, or prompts) you provide. For an AI agent to be relevant, it needs relevant data.
So, where does this all leave us?
The “year of the AI agent” won’t arrive because models get smarter. It’ll happen when we finally replace 70 years of brittle rules with adaptive systems that:
- Reason across environments
- Improve while working
- Focus on practical overhauls—not sci-fi fantasies
The key lies in restraint. Every API integration and feedback loop risks maintenance debt. Today’s successful agents handle jobs ill-suited for humans—like watching your servers or spotting fraud—without pretending to be geniuses.
LLMs didn’t invent agents, but they turned them from museum exhibits into workshop tools. The goal isn’t to build HAL 9000; it’s to make existing systems more thoughtful, one loop at a time.
If you’re exploring agentic workflows in production, Fusion brings this approach into the design and development stack.
It lets teams build agents that can read designs, understand components, generate code, and iterate in context, all using the systems they already rely on.