
I've hired a lot of developers over the years. More than a few of them have come in with a strong belief that our code needed heavy refactoring. But here's the thing: in almost every case, their newly refactored code was found by the other developers to be harder to understand and maintain. It also was generally slower and buggier too.
Now, don't get me wrong. Refactoring isn't inherently bad. It's a crucial part of keeping a codebase healthy. The problem is that bad refactoring is, well, bad. And it's surprisingly easy to fall into the trap of making things worse while trying to make them better.
So, let's get into what makes a good refactor versus a bad one, and how to avoid being that developer everyone dreads seeing near the codebase

Abstractions can be good. Abstractions can be bad. The key is knowing when and how to apply them. Let's look at some common pitfalls and how to avoid them.
One of the most common mistakes I've seen is when developers completely change the coding style during a refactor. This often happens when someone comes from a different background or has strong opinions about a particular programming paradigm.
Let's look at an example. Imagine we have a piece of code that needs some cleanup:
Before:
Bad refactor:
While this refactored version might appeal to functional programming enthusiasts, it introduces a new library (Ramda) and a completely different coding style. For a team not familiar with this approach, it could be a nightmare to maintain.
Good refactor:
This version improves the original code by using more idiomatic JavaScript methods like filter and map. It's more concise and easier to read, but it doesn't introduce a completely new paradigm or external dependencies.
I once hired someone who added tons of new abstractions without understanding the underlying code. They began grouping things that should not be grouped and were in the process of (intentionally) diverging over time. They consolidated some configurations that shouldn't have been (different APIs needed different configurations).
Before:
Bad refactor:
This refactor introduces a class with multiple methods, which might seem more "object-oriented", but it's actually more complex and harder to understand at a glance.
Good refactor:
This version breaks down the logic into small, reusable functions without introducing unnecessary complexity.
I've seen cases where developers update one part of the codebase to work completely differently from the rest, in an attempt to make it "better". This often leads to confusion and frustration for other developers who have to context-switch between different styles.
Let's say we have a React application where we consistently use React Query for data fetching:
Now, imagine a developer decides to use Redux Toolkit for just one component:
This inconsistency is frustrating because it introduces a completely different state management pattern for just one component.
A better approach would be to stick with React Query:
This version maintains consistency, using React Query for data fetching across the entire application. It's simpler and doesn't require other developers to learn a new pattern for just one component.
Remember, consistency in your codebase is important. If you need to introduce a new pattern, consider how you can get buy-in from your team first, rather than creating one-off inconsistencies.
One of the biggest problems I've seen is refactoring code while learning it, in order to learn it. This is a terrible idea. I've seen comments that you should work with a given piece of code for 6-9 months. Otherwise, you are likely to create bugs, hurt performance, etc.
Before:
Bad refactor:
The refactorer might think they're simplifying the code, but they've actually removed an important caching mechanism that was in place to reduce API calls and improve performance.
Good refactor:
This refactor maintains the caching behavior while potentially improving it by using a more sophisticated cache manager with expiration.
I joined a company once with horrible legacy code baggage. I led a project to migrate an ecommerce company to a new, modern, faster, better tech... angular.js
It turns out, this business was heavily dependent on SEO, and we built a slow and bloated single page app.
We shipped nothing for 2 years besides a slower, buggier, and less maintainable carbon copy of the website. Why? The people leading this (me - I am the asshole of this scenario) hadn't worked on this site before. I was young and dumb.
Let's look at a modern example of this mistake:
Bad refactor:
This approach might seem modern and clean, but it's entirely client-side rendered. For an e-commerce site that depends heavily on SEO, this could be disastrous.
Good refactor:
This Next.js-based approach provides server-side rendering out of the box, which is crucial for SEO. It also offers a better user experience with faster initial page loads and improved performance for users with slower connections. Remix would be equally good for this purpose, offering similar benefits for server-side rendering and SEO optimization.
I once hired someone who, on their first day working on our backend, immediately started refactoring code. We had a bunch of Firebase functions, some with different settings than others - like timeout and memory allocation.
Here's what our original setup looked like.
Before:
This person decided to wrap all these functions in one createApi function.
Bad refactor:
This refactor set all APIs to have the same settings, with no way to override per API. It's a problem because sometimes we need different settings for different functions.
A better approach would've been to allow the Firebase options to pass through per API
Good refactor:
This way, we keep the benefits of the abstraction while preserving the flexibility we need. When consolidating or abstracting, always think about the use cases you're serving. Don't sacrifice flexibility for the sake of "cleaner" code. Make sure your abstractions allow for the full range of functionality that the original implementation provided.
And seriously, understand the code before you start "improving" it. We had issues the next time we deployed some APIs that could've been avoided without this blind refactoring.
It's worth noting that you do need to refactor code. But do it right. Our code is not perfect, our code needs cleanup, but keep consistent with the codebase, be familiar with the code, be choosy about abstractions.
Here are some tips for successful refactoring:
- Be incremental: Make small, manageable changes rather than sweeping rewrites.
- Deeply understand code before doing significant refactors or new abstractions.
- Match the existing code style: Consistency is key for maintainability.
- Avoid too many new abstractions: Keep it simple unless complexity is truly warranted.
- Avoid adding new libraries, especially of a very different programming style, without buy-in from the team.
- Write tests before refactoring and update them as you go. This ensures you're maintaining the original functionality.
- Hold your coworkers accountable to these principles.
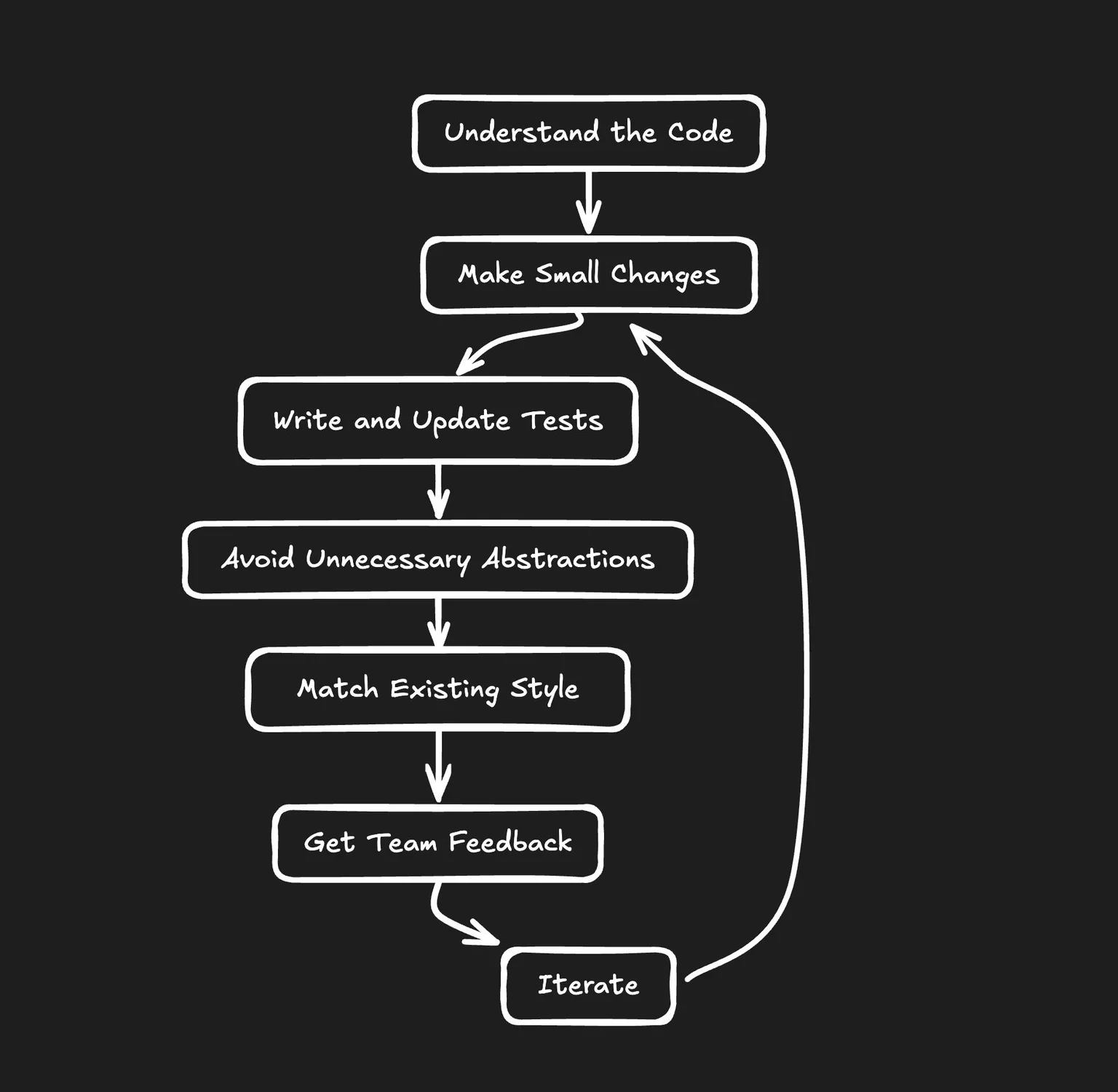
To help ensure your refactors are beneficial rather than harmful, consider the following techniques and tools:
Use linting tools to enforce consistent code style and catch potential issues. Prettier can help auto-format to a consistent style, while Eslint can help with more nuanced consistency checks that you can easily customize with your own plugins.
Implement thorough code reviews to get feedback from your peers before merging refactored code. This helps catch potential issues early and ensures the refactored code aligns with team standards and expectations.
Write and run tests to ensure your refactored code doesn't break existing functionality. Vitest is a particularly fast, solid, and easy-to-use test runner that requires zero configuration by default. For visual testing, consider using Storybook. React Testing Library is a great set of utilities for testing React components (there are Angular and more variants as well).
Let AI help you with your refactoring efforts, at least those that are able to match your existing coding style and conventions.
One tool that's particularly useful for maintaining consistency while coding frontends is Visual Copilot. This AI-powered tool can help you turn designs into code while matching your existing coding style and correctly leveraging your design system components and tokens.
Refactoring is a necessary part of software development, but it needs to be done thoughtfully and with respect for the existing codebase and team dynamics. The goal of refactoring is to improve the internal structure of the code without changing its external behavior.
Remember, the best refactors are often invisible to the end-user but make life significantly easier for developers. They improve readability, maintainability, and efficiency without disrupting the overall system.
The next time you feel the urge to make "big plans" for a piece of code, take a step back. Understand it thoroughly, consider the impact of your changes, and make incremental improvements that your team will thank you for.
Your future self (and your colleagues) will appreciate the thoughtful approach to keeping the codebase clean and maintainable.
Oh also do you like YouTube vids? Theres a video on this too from yours truly:
Hi, I'm Steve, the CEO of Builder.io. We make dev tools, like a Visual Copilot which turns Figma designs into spankingly good code. You should try it out.